Featured
May 26, 2026
The Complete UAR Checklist: How to Automate Access Certifications and Strengthen Identity Security


Another week, another ShinyHunters headline.
First Canvas. Then 7-Eleven and Charter Communications. A roughly combined 317.2 million identities compromised in these three breaches, just in the last month alone. The details of these incidents are still emerging, and in moments like this it is important not to overstate what we know. But what is already clear is that the same attacker name keeps showing up in conversations about data theft, extortion, SaaS platforms, and trusted enterprise access.
That is the part worth paying attention to.
The security industry still talks about breaches as if attackers are always finding more sophisticated ways to break in. Sometimes they are. But increasingly, the story is different. Attackers are not always breaking through the front door. They are finding identities that already have keys.
What if the real story is not that attackers have become dramatically better at bypassing the enterprise?
What if the real story is that attackers have become exceptionally good at using the trust enterprises have already created?
That is what makes ShinyHunters such an important case study. Not because the group is unique in every tactic it uses, and not because every incident follows the exact same pattern. They are important because their campaigns keep exposing the same uncomfortable truth: identity has become one of the most valuable attack surfaces in the modern enterprise.
The recent Canvas incident is still being investigated, but it has already shown the operational impact of compromising a widely used digital platform. Instructure, the company behind Canvas, said it reached an agreement with the attackers to have stolen data deleted, though the company did not disclose the terms or confirm whether a ransom was paid. The attackers had claimed access to data tied to millions of students, teachers, and staff, and the incident disrupted schools during one of the most sensitive windows of the academic year.
The 7-Eleven incident followed a different path. The company confirmed unauthorized access to systems used to store franchisee documents. Reports linked the incident to ShinyHunters and described exposed franchise applicant data, including sensitive personal information. Some reports said stolen files were published after 7-Eleven declined to pay.
Different organizations. Different environments. Different circumstances.
The economics look familiar.
Sensitive data is exposed. Operations are disrupted. Organizations are pressured to negotiate. Customers, students, employees, partners, or applicants are left wondering where their information went and what happens next.
This is why these attacks continue. They work. The criminal economy around data theft and extortion is not built on novelty. It is built on repeatability. Attackers do not need a new zero-day every week if they can find exposed credentials, overprivileged accounts, vulnerable integrations, weakly governed service accounts, or trusted access paths that lead to valuable data.
That is the pattern behind the headlines.
The most important ShinyHunters campaign was not the one that happened in the last month.
It was Snowflake.
When the Snowflake campaign became public, the initial instinct across the industry was to look for the platform flaw. That is how we have been trained to think about breaches. A major cloud platform is involved, large volumes of customer data are exposed, and the first question becomes: what vulnerability did the attacker exploit?
But the Snowflake story was more instructive than that. Mandiant said it found no evidence that unauthorized access stemmed from a breach of Snowflake’s enterprise environment. Instead, the incidents it investigated were traced back to compromised customer credentials. In many cases, those credentials had been previously stolen by infostealer malware. Some accounts reportedly lacked multi-factor authentication. Attackers then used those legitimate credentials to access customer Snowflake instances, enumerate data, and exfiltrate information.
That should have changed the industry conversation.
The attack did not begin with a vulnerability in the traditional sense. It began with an identity. The attackers did not need to defeat every control in the environment. They needed to find a trusted path that already existed.
From there, the playbook becomes familiar. Use stolen credentials. Access a cloud or SaaS environment. Determine what the identity can reach. Locate high-value data. Extract it. Extort the victim.
The most important lesson from Snowflake was not that attackers had become better at breaking in. It was that attackers had become better at using the trust we already created for them.
That distinction matters because it changes how defenders need to think. If the threat is only exploitation, then the solution is patching, hardening, and vulnerability management. Those things still matter. But if the threat is trusted access being misused, the problem becomes much broader. It becomes a question of identity governance, privilege, context, monitoring, and trust.
Snowflake became one of the clearest examples of a larger shift already underway. The enterprise attack surface is no longer defined only by networks, endpoints, and applications. It is increasingly defined by identities and the access paths those identities create.
Groups like ShinyHunters understand something many organizations are still struggling to operationalize: the fastest path to valuable data is often not through infrastructure. It is through identity.
This does not mean every ShinyHunters incident is purely an identity attack. Real-world breaches are messier than that. They involve social engineering, stolen credentials, exposed systems, third-party platforms, weak configurations, and gaps in monitoring. But across many of these campaigns, the theme is consistent. The attacker looks for a way to inherit trust.
That trust may come from a stolen employee credential. It may come from a compromised contractor account. It may come from an account without MFA. It may come from a service account that has accumulated far more access than anyone realizes. It may come from a SaaS integration connected to sensitive data. It may come from an identity provider relationship, an API token, or an admin workflow that was designed for speed and convenience rather than adversarial use.
Attackers do not care whether an identity belongs to a human, a workload, a third-party integration, or an AI agent. They care whether that identity can take them somewhere valuable.
That is the shift.
For a long time, identity was treated primarily as a control for access. Authenticate the user. Grant the right permission. Remove access when someone leaves. Review access periodically for compliance. That model made sense when the enterprise was simpler, applications were fewer, and most access was tied to human employees inside relatively well-defined boundaries.
That world no longer exists.
The average enterprise has lost track of how many identities it actually has.
Not users. Identities.
There was a time when identity mostly meant employees. Then contractors became a meaningful part of the workforce. Then partners and vendors were brought into internal systems. Then SaaS applications exploded. Then cloud infrastructure created workloads, roles, and service accounts at a scale most governance programs were not designed to handle. Then APIs and third-party integrations connected systems that were never originally designed to work together. Now AI agents are entering the environment, taking actions on behalf of users, systems, and business processes.
Every one of those changes created new identities. Every new identity created permissions. Every permission created trust. Every trust relationship created a possible attack path.
This is the part many organizations cannot see clearly. They may know how many employees they have. They may know how many applications they manage. They may have a list of privileged users in one system or a quarterly access review process in another. But far fewer can answer the more important question: how many identities exist across the entire environment, what can they reach, and how do they connect to one another?
That is where the risk accumulates.
A service account gets created for a project and never removed. A contractor keeps access after the engagement ends. A SaaS integration is granted broad permissions because it was faster than scoping them properly. A cloud role inherits access from another role. A machine identity is exempted from the controls applied to human users. An AI agent is connected to systems before the governance model is fully understood.
None of these decisions may look catastrophic in isolation. Most of them happen for reasonable business reasons. Teams are moving quickly. Applications need to connect. Data needs to flow. Employees need to work. Automation needs to run.
But attackers do not experience the environment as isolated decisions. They experience it as a graph of trust.
That is what makes identity-based attacks so effective. The attacker does not need to understand the company the way an org chart describes it. They only need to understand the paths between identities, systems, and data. If one identity gives them access to another system, and that system gives them access to another dataset, the business logic behind those connections is irrelevant. The path exists.
And if the path exists, an attacker can use it.
This is why many security leaders are starting to ask a different set of questions than they were five years ago. The old questions still matter: who has access, who approved it, and when was it last reviewed? But they are no longer enough.
The better questions are more contextual. Which identities are overprivileged relative to what they actually do? Which service accounts have accumulated access no human would ever be allowed to keep? Which machine identities can reach sensitive systems? Which third-party integrations have permissions that no one has reviewed in months? Which AI agents are beginning to act with privileges inherited from the humans or systems that created them? Which trusted relationships would become dangerous if a single credential were compromised?
Those are not just compliance questions. They are security questions.
They are also difficult questions to answer with legacy identity tooling. Traditional IAM and IGA systems were built around granting access, removing access, and proving to auditors that access was reviewed. That work remains important, but it was not designed for the speed, complexity, and adversarial pressure of the current environment.
The question is no longer only whether an identity is authorized. The question is what becomes possible once that identity is trusted.
That is exactly what the ShinyHunters playbook keeps demonstrating. The breach begins with access. The damage comes from what that access can reach.
The lesson from ShinyHunters is not that organizations need more security tools. It is that they need a better understanding of trust.
The challenge with identity-based attacks is that the attacker rarely starts with their final objective. They start with a foothold. A credential. A service account. A contractor account. A SaaS integration. An API token. Then they follow the trust relationships that already exist inside the environment.
That means organizations need to focus on four things:
The goal is not to eliminate trust. The goal is to understand it well enough that attackers cannot exploit it first.
This shift is one of the reasons we started Linx. Not because another attacker group made the news, and not because fear is a compelling business strategy. We started Linx because we saw the enterprise changing faster than the identity tools designed to secure it.
The challenge facing security teams today is not simply managing identities. It is understanding trust across an environment that has become dramatically more complex over the last decade. Human identities are only one part of the equation. Organizations now need to govern machine identities, service accounts, cloud workloads, SaaS applications, APIs, third-party integrations, contractors, vendors, and AI agents. Every one of those identities creates access. Every access decision creates a relationship. Every relationship changes the shape of the attack surface.
Legacy identity governance was built for a world where periodic review was enough. Modern identity security requires continuous understanding. It requires knowing not only who has access, but why they have it, whether they still need it, what risk it creates, and what an attacker could do with it.
That is the problem Linx is focused on solving.
The lesson from ShinyHunters is not that attackers are becoming unstoppable. It is that attackers are following the architecture we have built. And the architecture we have built increasingly runs on identity.
I think the next decade of security will be defined by a simple idea: organizations will need to continuously validate trust across their environments, not just authenticate it once.
Historically, identity programs have focused on granting access, removing access, and periodically reviewing access. That model was built for a world where identities were relatively static and environments changed slowly. Today’s environments are dynamic. Permissions change constantly. New identities are created every day. Machine identities, AI agents, and automated workloads are introducing entirely new categories of access that most organizations are still learning how to govern.
The companies that succeed will not necessarily be the ones that react fastest to the next breach. They will be the ones that understand their trust relationships deeply enough to identify and eliminate attack paths before attackers can exploit them.
That is the future we are building toward at Linx.
And if the last few years of ShinyHunters headlines have taught us anything, it is that the industry is moving there whether we are ready or not.
At Linx Security, we help organizations build robust identity security that addresses each stage of the attack chain. Book a demo with one of our engineers to learn more about how we can keep your systems safe from identity breaches.

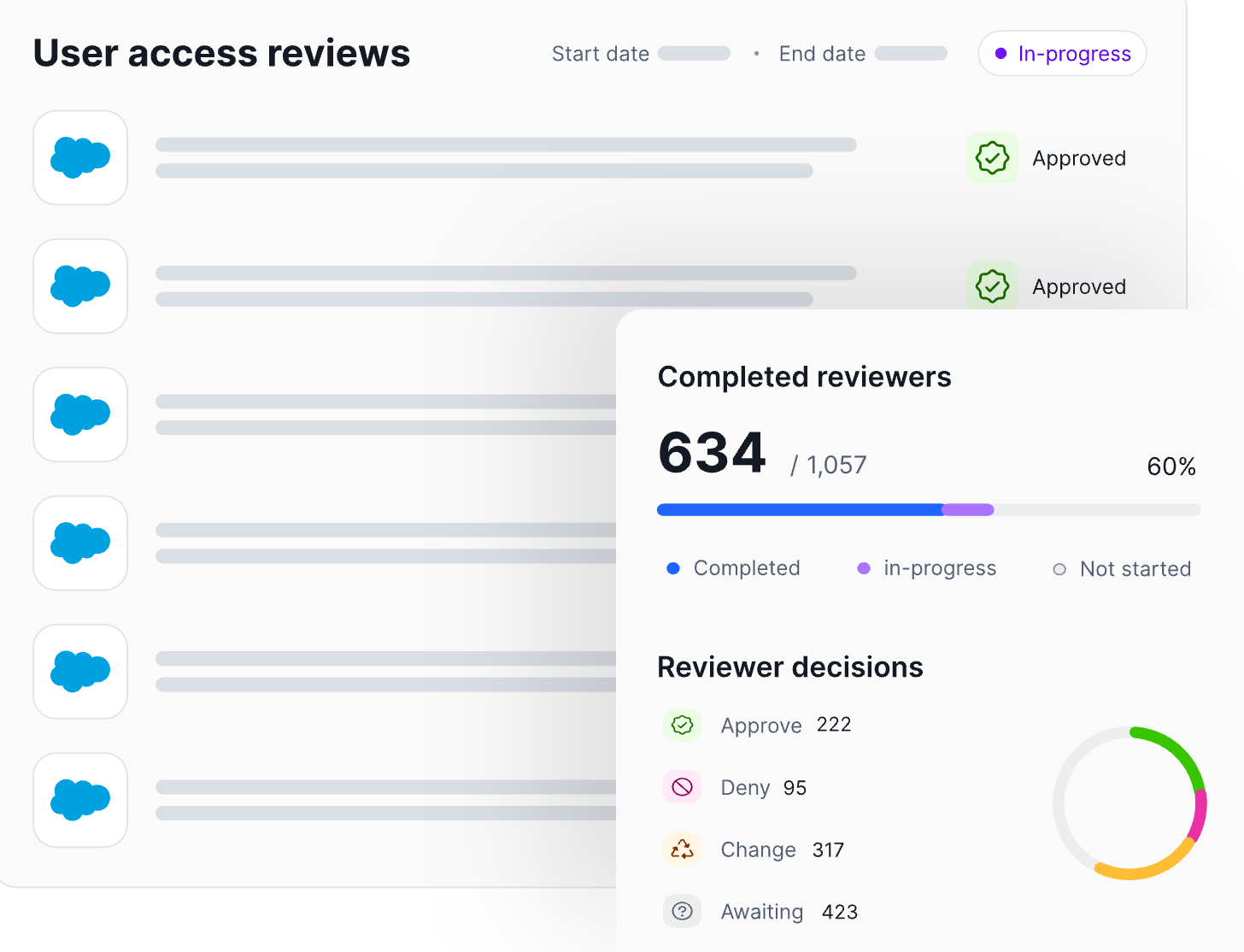
If your organization runs user access reviews, you already know the pain. Spreadsheets, manual exports, managers rubber-stamping hundreds of permissions in a single afternoon, audit evidence scattered across email threads. The process is supposed to enforce least privilege and satisfy auditors but in most organizations, it does neither well.
This post covers what an effective access review program actually looks like in practice, how to automate it, and how to fix the most common failure modes. If you came here for a checklist, you can download the complete user access review checklist here.
A user access review (UAR) — also called an access certification, entitlement review, or certification campaign — is the process of periodically validating who has access to which systems and data, and whether those permissions are still appropriate. Organizations run them to enforce least privilege, meet compliance requirements, and reduce the risk of unauthorized access.
Most UAR programs fail for the same handful of reasons:
A complete UAR program follows six stages. If any of these are missing or poorly executed, that's where risk accumulates and where auditors find gaps.
Planning & Scoping. Define which systems, applications, and data repositories are in scope before anything else. Prioritize by sensitivity, with financial systems, customer data, and privileged infrastructure first. Confirm which compliance frameworks apply and what they require.
Data Collection. Pull current access lists from all in-scope systems to get a clean, consolidated snapshot of who has access to what, at what permission level. This means normalizing disparate permission formats, flagging orphaned accounts and terminated users, and attaching context (last activity, business role, usage patterns) to every record before review begins.
Reviewer Assignment. Assign the right reviewer to every access record based on system ownership, management hierarchy, or data sensitivity. Ensure no record goes unassigned, set clear deadlines, and brief reviewers on what is expected: explicit Approve/Deny decisions, not passive acknowledgment.
Access Certification & Remediation. Reviewers approve or revoke access, and failing to reach a 100% review rate often results in having to restart the process, so be sure to reach 100%. Ways to streamline this stage include flagging the highest-risk permissions first, providing context-rich recommendations to prevent rubber-stamping, and sending reminders to keep the process on schedule.
Documentation & Evidence Collection. Capture a full audit trail: who reviewed what, when decisions were made, and what was revoked. Every decision needs a timestamp, a reviewer identity, and a rationale, stored in an immutable format that an auditor can reconstruct on demand.
Reporting & Continuous Improvement. Formally close the cycle with a summary report covering scope, completion rate, access modified or revoked, and remediation times. Use the findings to identify bottlenecks, address rubber-stamping patterns, and refine the next cycle toward a more automated, continuous review model.
Download the complete UAR Checklist →

Automation is the highest-leverage improvement available to most UAR programs. Here's what it looks like at each stage:
Continuous data collection. Automated platforms aggregate identity and permission data across all connected environments in real time, eliminating manual exports and ensuring reviewers always see current data. This includes automatically surfacing known bad access — orphaned accounts, dormant privileges, and accounts belonging to terminated users — as well as unknown bad access, such as permissions that deviate significantly from peer baselines and wouldn't be caught without behavioral analysis.
AI-driven risk prioritization. Machine learning ranks entitlements by risk, surfacing the permissions most likely to represent a genuine threat. Reviewers focus on what matters instead of weighing every record equally. AI serves as a "bridge" to solving the rubber-stamping problem and increasing review speed.
Context-enriched reviewer workflows. Reviewers receive pre-enriched access lists with last activity, business role, and AI-generated recommendations, replacing hours of cross-referencing with immediate, actionable insight.
API-driven remediation. When access is denied, revocation triggers automatically via API. No tickets, no lag, no waiting for IT to action the change.
Continuous compliance evidence. Every decision is logged, timestamped, and rationale-tagged in an immutable audit trail. Audit readiness becomes a permanent state rather than a quarterly fire drill.
Rubber-stamping happens when reviewers are overwhelmed by volume and lack the context to make real decisions, so they approve everything. It is the single biggest threat to UAR program validity, and it cannot be solved by reminding managers to "be more thorough."
The fix is structural:
Eliminate friction. A clean interface with structured Approve/Deny captures decisions faster than a spreadsheet and produces better audit evidence.
An audit trail isn't a log of reviews completed — it's a record of every decision, with full context, that an auditor can reconstruct months or years later.
A defensible audit trail requires:
Manual processes can technically produce all of this. They almost never do.
The best practices above point you in the right direction. The checklist gives you the full roadmap — every step of the UAR lifecycle, what good looks like, and how to automate it.
The highest-leverage improvements to any UAR program:
Linx Security is a next-generation modern identity governance platform purpose-built to make user access reviews continuous, intelligent, and measurable. With a graph-powered view of every human and non-human identity in your environment, and AI-driven workflows to act on what it surfaces, Linx handles the full UAR lifecycle in one platform.
What takes most teams weeks takes Linx days.
See Linx in action: book a demo at linx.security/demo
Access certifications are the formal, compliance-driven step of certifying access, often tied to frameworks like SOC 2 or SOX, while user access reviews is a broader term covering the full lifecycle. In practice the terms are often used interchangeably. Other industry terms for the same general practice include entitlement reviews, certification campaigns, and permission audits. The goal is the same regardless of terminology: ensure permissions are appropriate, minimal, and current.
By using an identity governance platform that continuously aggregates permission data, enriches it with risk scores and context, delivers structured workflows to reviewers, and triggers automatic remediation on denial. Automation removes the manual exports, ticketing, and chasing that slow traditional reviews down.
Most frameworks require quarterly reviews for sensitive systems and annual reviews for lower-risk apps. Mature programs are shifting to continuous monitoring, where anomalies trigger reviews in real time rather than on a fixed cadence.
Reviewing without context, relying on manual data collection, failing to automate remediation, and treating documentation as a separate task rather than a byproduct of the review process.
Least privilege means every user has access only to what they need and nothing more. Access reviews are the primary mechanism for identifying and revoking the excess permissions that accumulate over time as roles change.
SOC 2, ISO 27001, HIPAA, SOX, and PCI DSS all require some form of periodic access review or certification. Demonstrating that permissions are actively managed and promptly remediated is a baseline expectation across nearly every major framework.
Reviewer fatigue is when managers are so overwhelmed by review volume that they approve everything without scrutiny. The fix is filtering to high-risk records only, enriching each one with context and recommendations, and removing friction from the decision interface.
Just-in-time (JIT) access grants permissions only for the duration of a specific task, then automatically revokes them. It prevents standing privileges from accumulating in the first place, shrinking both the attack surface and the review workload.
Completion rate is the most-tracked metric but the least meaningful. Better indicators: detection-to-remediation time, reviewer approval rate, and percentage of access modified or revoked per cycle.
If you’re evaluating identity governance and administration (IGA) solutions in 2026, you already know that the average enterprise has more non-human identities than human ones. At the same time, identity-related breaches continue to rise, and the traditional process of manually reviewing access or defining static roles is simply too slow. A strong IGA platform should handle all of these challenges out of the box.
In this article, we’ll explore the top 10 IGA tools to consider, organized by category, so you can quickly identify what type of platform suits your organization.
Modern IGA solutions automate the full identity lifecycle and continuously enforce the principle of least privilege across human and non-human identities.
Founded: 2023
Headquarters: New York, New York
Category: AI-native IGA & Identity Security
Deployment model: SaaS (cloud-native)
Customer rating: 5/5 on Gartner Peer Insights
Linx is best for organizations that want a modern, AI-native IGA solution with fast deployment, real-time governance, and strong automation across both human and non-human identities.
Linx is an AI-native platform that combines deep identity visibility, automated governance, and continuous security enforcement into a single product. At its core is the Linx Identity Graph, which normalizes and correlates data across human, non-human, and agentic identities, mapping the full access path from identity to resource.
The Linx Identity Graph empowers you to make informed decisions: You understand, at a glance, who had access, how they gained it, whether they used it, and the blast radius in the case of a compromise. With a single click, you can remediate the root cause of an issue straight from the Identity Graph.
Linx gives you this full visibility into your identity environment by pulling data from every application and system you use. This full coverage is thanks to an extensive library of out-of-the-box connectors, which also include legacy and on-premises systems that many competitors overlook.
Linx also offers automated access review and remediation workflows that continuously evaluate entitlements and detect drift. When access needs to be adjusted or even revoked, remediation happens directly inside the platform: You don’t need any ticketing loops or manual intervention.
Additionally, Linx has introduced Autopilot, the first AI agent built for identity security and governance. Unlike AI systems that only operate on demand, Autopilot monitors identity environments 24/7, detects changes in real time, evaluates risk in context, and takes action to remediate issues. With Autopilot, you get an always-on, autonomous coverage that eliminates the manual work of chasing access reviews, freeing up security teams to focus on implementing new features rather than firefighting.
The bottom line? With Linx, you get a single solution that covers visibility, governance, lifecycle automation, and identity security without the complexity and cost of legacy IGA vendors.
Founded: 2020
Headquarters: Los Gatos, California
Category: Identity Security
Deployment model: SaaS (cloud-native)
Customer rating: 4.8/5 on Gartner Peer Insights
Veza is best for security teams that need deep visibility into permissions and authorization across cloud and data systems, especially across complex data environments like Snowflake, AWS, and custom applications.
Veza's Access Graph maps an organization’s entire identity ecosystem, with a deep focus on data and infrastructure. This approach makes Veza strong for access visibility and least-privilege enforcement.
Recently, Veza has introduced Access Agents, which are AI agents designed for governance tasks. Veza has also invested in AI agent security to provide visibility into MCP servers, AI agent permissions, and LLM infrastructure.
Pros
Cons
(Note: ServiceNow acquired Veza in December 2025)
Founded: 2020
Headquarters: San Francisco, California
Category: SaaS Management IGA
Deployment model: SaaS (cloud-native)
Customer rating: 4.6/5 on Gartner Peer Insights
Lumos is best for mid-market companies focused on automating access requests and approvals across SaaS apps, especially those prioritizing employee self-service and productivity.
Lumos is a modern IGA platform that offers real-time visibility into enterprise SaaS ecosystems and allows companies to automate access requests through channels like Slack. When you connect Lumos to your organization’s cloud applications, it can check and map all user permissions and simplify access requests through a self-service portal.
Pros
Cons
Founded: 2020
Headquarters: San Francisco, California
Category: Modern IGA & Authorization
Deployment model: SaaS (cloud-native)
Customer rating: Not yet listed
Opal Security is best for engineering-heavy organizations that want granular, real-time access governance with deep developer tooling integrations and just-in-time access controls.
Opal Security is an authorization reasoning platform with an intelligent data layer that continuously analyzes access behavior across cloud, SaaS, and on-prem environments. Developer-native integrations and a 2025 Risk Layer for AI agent governance round out the platform.
Legacy IGA platforms are traditionally on-premises identity governance tools that rely heavily on manual workflows and static roles. They usually need dedicated teams to deploy and manage them.
Founded: 2005
Headquarters: Austin, Texas
Category: Enterprise IGA
Deployment model: SaaS + Hybrid
Customer rating: 4.8/5 on Gartner Peer Insights
SailPoint is best for large enterprises in regulated industries that need a battle-tested IGA platform with a mature SI partner ecosystem and the flexibility to run cloud, on-prem, or both.
SailPoint offers AI-powered access reviews, a broad library of connectors, and lifecycle automations. Its strengths are scale and depth, and it can help you govern tens of thousands of identities across a complex hybrid environment.
Founded: 2005
Headquarters: El Segundo, California
Category: Cloud-first IGA
Deployment model: SaaS
Customer rating: 4.8/5 on Gartner Peer Insights
Saviynt is best for enterprises looking to consolidate IGA, PAM, and Application Access Governance into a single platform, particularly those running complex ERP environments like SAP or Oracle that require strong Separation of Duties enforcement.
Saviynt is a cloud-native IGA platform that provides identity governance and cloud infrastructure entitlement management (CIEM) in a single solution. It has machine learning capabilities, and its built-in IdentityBot RPA engine automates provisioning tasks. It’s a good choice if you want a platform that covers IGA, PAM, and CIEM without having to buy three separate tools.
Founded: 2000
Headquarters: Copenhagen, Denmark
Category: IGA
Deployment model: SaaS + On-prem
Customer rating: 4.6/5 on Gartner Peer Insights
Omada is best for European enterprises and organizations with strict GDPR, NIS2, or cross-border data residency requirements that need deep hybrid environment support and a strong implementation track record.
Omada Identity Cloud’s best features are code-free configuration, AI-powered analytics, and role-based access control. Omada can be a good choice for mid-to-large companies that need a structured, compliance-focused IGA solution with strong support for hybrid environments.
Pros
Cons
Identity and SaaS governance platforms prioritize fast deployment and visibility, but they often fall short of full lifecycle management.
Founded: 2009
Headquarters: San Francisco, California
Category: IGA (add-on module to Okta platform)
Deployment model: SaaS
Customer rating: 4.2/5 on Gartner Peer Insights
Okta Identity Governance is best for companies already using Okta that want to extend their IAM platform into lightweight IGA with minimal additional tooling.
Okta Identity Governance (OIG) extends Okta’s core identity platform. It leverages Okta’s existing directory and SSO integrations to add lifecycle management, periodic reviews, and audits to verify who has access to what without requiring a separate IGA deployment.
Founded: 1999 (CyberArk) / 2019 (Zilla)
Headquarters: Petach Tikva, Israel
Category: PAM + IGA
Deployment model: SaaS + Hybrid
Customer rating: 4.8/5 on Gartner Peer Insights
CyberArk Identity Security Platform is best for organizations that already rely on CyberArk for privileged access management and want to extend modern IGA capabilities through the same platform rather than buying a standalone tool.
CyberArk is known for its robust privileged access management (PAM) capabilities and has expanded to offer broader identity security. CyberArk can help you secure your high-risk credentials (enforcing just-in-time access and recording privileged sessions), and it also provides features like adaptive MFA and identity lifecycle management.
Note: Palo Alto Networks acquired CyberArk in February 2026.
Founded: 2020
Headquarters: Milpitas, California
Category: SaaS Management + IGA
Deployment model: SaaS (cloud-native)
Customer rating: 4.6/5 on Gartner Peer Insights
Zluri is best for mid-market companies looking for a simple, SaaS-first IGA solution with strong SaaS discovery and application management capabilities, without the overhead of an enterprise-grade IGA deployment.
Zluri is a SaaS management and identity governance platform that uses its discovery engine to surface all applications in your environment, including shadow IT. This comprehensive visibility enables IT and security teams to see exactly which tools are being accessed and by whom, providing a strong foundation for governance and cost optimization.
Modern IGA platforms are cloud-native, AI-driven systems that continuously govern identity access in real time, while legacy IGA platforms are on-premises tools built for periodic, manual governance. Legacy platforms rely on scheduled access reviews, manual provisioning, and dedicated engineering teams. Modern IGA replaces that model with continuous monitoring and automated remediation that scales across human, non-human, and AI agent identities, with faster deployment and lower total cost of ownership.
Several IGA platforms have introduced AI agent governance capabilities, including Linx, Veza, Opal Security, SailPoint, Saviynt, and CyberArk. Linx governs AI agents and offers continuous drift monitoring. Veza (now part of ServiceNow) provides visibility into MCP servers and LLM infrastructure. Opal Security has introduced a Risk Layer specifically for agentic authorization requests and ships a native MCP server for AI-driven access automation. SailPoint has extended governance to AI agents in Salesforce, ServiceNow, and Snowflake. Saviynt and CyberArk have expanded non-human identity coverage to include agent credentials.
SaaS IGA is a cloud-hosted service managed by the vendor; on-premises IGA is software installed and maintained on your own infrastructure. Most modern IGA vendors have moved exclusively to SaaS; legacy platforms like SailPoint IdentityIQ remain available on-premises for organizations with strict data sovereignty requirements.
Okta and Microsoft Entra are identity providers that handle authentication and basic lifecycle management, but they are not full identity governance platforms. IGA addresses a complementary set of problems: enforcing least privilege, automating access reviews, managing separation of duties, and governing non-human identities. Both Okta and Microsoft offer governance add-ons, but organizations with hybrid infrastructure, complex compliance requirements, or applications outside those ecosystems typically need a purpose-built IGA platform.
For mid-market organizations, the best-fit platforms prioritize fast deployment and low operational burden: Lumos, Zluri, Linx, and Opal Security are strong options that deliver value without a dedicated IAM team.
For large enterprises in regulated industries, SailPoint, Saviynt, and Linx offer the compliance automation, ERP integration, and hybrid environment support that complex organizations require.
It depends on the platform and the complexity of your environment. Legacy platforms like SailPoint IdentityIQ almost always require vendor-led or partner-led professional services, with implementations taking 6 to 12 months and services costs that can match or exceed the software license. Modern cloud-native platforms like Linx, Lumos, and Zluri are designed to reduce or eliminate that dependency. When evaluating vendors, ask whether professional services are required or optional and whether implementation costs are included in the platform fee.
The top IGA tools in 2026 fall into three categories. Modern platforms include Linx Security, Lumos, Veza (now part of ServiceNow), and Opal Security. Established enterprise platforms include SailPoint and Saviynt, which offer deep compliance automation at the cost of implementation complexity. Okta Identity Governance, CyberArk (which acquired Zilla Security in 2025 and was acquired by Palo Alto Networks in 2026), Omada, and Zluri round out the category with strengths in ecosystem integration, privileged access, European compliance, and SaaS management respectively.
The most important factors when evaluating IGA vendors are deployment speed, AI capability, connector coverage, and total cost of ownership. Ask whether the platform requires professional services or can be deployed by your internal team. Distinguish between AI-native platforms and those with AI bolted onto a legacy system. Get the full TCO picture including licensing, implementation, and any features charged separately. Lastly, analyst recognition from Gartner or Forrester provides a useful independent quality signal.
In 2026, the direction of the IGA market is clear: Speed, AI-native automation and augmentation, in-platform remediation, and out-of-the-box integrations are now non-negotiable. The best modern IGA tools combine these features with full visibility and intuitive identity lifecycle management.
This is where Linx Security leads the pack. Linx provides full identity governance and immediate time-to-value through its zero-configuration connectors across cloud, SaaS, and on-prem environments. It’s purpose-built for ease of use: You don’t need professional services to deploy or operate Linx.
Better yet, Linx offers round-the-clock, AI-driven coverage so that no identity issues fall through the cracks. Linx Security’s Autopilot continuously analyzes identity risks and auto-remediates policy violations before they become security incidents.
If you are reviewing IGA vendors, read this blog to understand what are the 10 questions you need to ask when evaluating IGA solutions.
At the same time, if you’re looking for an IGA platform that checks all of the boxes, book a demo with Linx Security to experience what an industry-leading IGA can do.

We shipped Autopilot 10 weeks ago. Autopilot is our autonomous AI agent for identity governance, designed to continuously monitor identity environments, evaluate risk in context, and take action without waiting for human review.
Since then, what's surprised me most isn't about the product. It's about what enterprise security leaders actually want from autonomy, and how dramatically that differs from what the identity industry has been selling them for the last decade.
What follows are notes from inside that learning. Real conversations with the security teams running Autopilot today, plus the CISOs, Heads of IAM, and identity architects evaluating it for the next wave. Across retail, financial services, healthcare, hospitality, and Big Tech. The patterns showed up faster than I expected. They were more uniform than I expected. And one of them surprised me.
Different industries. Different sizes. Different titles. The same line, in slightly different words.
A CISO at a global financial services firm put it most directly: "I don't need another alert and a warning. I need something to take action."
A senior identity architect at a Fortune 500 retailer framed the other side of the same coin: "I need a log of every action the agent takes, with the reasoning. We still work with auditors, and 'the system decided' isn't a good enough answer."
On the surface those two statements look opposite. One asks for autonomy. The other asks for documentation. But they're the same insight, said from two seats: enterprises want autonomous action, and they want a clean audit trail of every action that gets taken. Autonomy without auditability is a non-starter in any regulated environment. Auditability without autonomy is the status quo we've all been stuck with for a decade.
The thing that's been mis-sold for ten years is that autonomy and accountability are opposites. They're not. They're complementary. Customers are not asking us to choose between "fully automated" and "humans review everything." They're asking for a system that does the work and shows its work, at the same time, every time.
Almost nobody in the legacy identity governance market has built that combination. They've built two products: rules engines that fire alerts, and access reviews that get rubber-stamped quarterly. Neither is autonomous. Neither produces the kind of action-level audit trail a regulated environment can defend. Both are exhausting.
We built Autopilot to do both: take the action, and produce a complete, defensible audit log of every step it took and why. That's the unlock.
I expected we'd have to convince buyers to start small with autonomy. To meet them where they were, hand-hold them through a phased rollout, and prove value before unlocking more.
Instead, security teams are articulating the pattern back to us before we pitch it.
A Head of Security at a healthcare enterprise said it clearly: "Trust in autonomy builds over time. So maybe it prompts me first, but as we get comfortable with it, this just needs to run. I've got an agent for that. It just happens."
Almost every conversation followed this shape. Phase 1: the agent investigates, surfaces a recommendation, a human clicks. Phase 2: an admin pre-approves classes of action, and the agent executes. Then, eventually, full autonomy on narrow, well-bounded tasks.
This is buyers leading the architecture, not vendors prescribing it. That's a tell. It means the market has matured past the question of whether autonomy belongs in identity governance and moved to the question of how to operationalize it without losing accountability.
The teams we're working with don't need convincing. They need a credible path. We've built that path into Autopilot from day one.
Every demo we ran ended in a comparison. Security leaders held Autopilot up against their existing IGA stack, and named what was breaking.
The list rhymes across industries.
Quarterly access reviews are theater. A senior security leader at a global financial data firm asked his team, almost rhetorically, "would you rather have compliance or security?" The framing was sharp because it was honest. Quarterly UAR cycles exist for auditors, not for defenders. Everybody in the room knows it. Nobody in legacy IGA has the architecture to fix it, because their architecture is built around the cycle. Ours isn't.
Rules-based systems produce more alerts, not more action. Several CISOs described arriving at security programs that had ten thousand identity rules and one human staring at the dashboard. The rules weren't wrong. They were just disconnected from the question of who actually had the authority to act on them. Autopilot collapses that gap.
Legacy deployments take years and don't reduce manual work. One enterprise security leader described getting more value in three weeks of running Linx than in three years of running two of the largest legacy IGA platforms combined. I'm not going to name the platforms. The point wasn't that those tools are bad. It's that they were built for a different era of identity, one where humans had time to be in the loop on every decision. That era is over.
One enterprise we engaged with was running five identity products simultaneously. Five. They had to deprovision one because it was disrupting the others. This is what the end-state of "buy more tools" looks like. It's not a security program. It's a tax on the security team. We replace that stack with one platform that does what those five together couldn't do.
These aren't edge cases. They're the pattern.
When teams pick their first Autopilot deployment, three patterns dominate.
Admin Drift Monitor. Listens for any access change that elevates someone to admin. Runs a peer comparison and a JIT/access-profile check. Only fires if it finds no justification for the elevation. The reason this one wins is concrete: it produces almost zero false positives, because the bar for "should this human be admin" is exceptionally well-defined inside any mature security program. Teams audit the agent's reasoning easily. They trust it within days. Then they extend it.
UAR Reviewer Classifier. Continuously evaluates entitlements during access review campaigns and pre-recommends approve/deny before the human even opens the review. The pattern: stop asking humans to be the first decision-makers. Make them the second. The human's time is worth far more on the close calls than on the obvious ones.
Access Profile Tuner. The next agent we're shipping. It continuously refines access profiles based on real usage patterns, tightening over-provisioned access automatically and surfacing the gap between what someone has and what they actually use day to day. Same architectural pattern as the first two: narrow scope, accountable action, the human as the second decision-maker, not the first.
What links these three agents is what they aren't. They aren't general-purpose AI assistants. They aren't conversational chatbots. They aren't models that "help you think about identity." They're narrow, accountable, single-purpose agents. They do one thing. They do it well. They show their work.
This is the part of the next 12 months in identity that I think the industry is going to get wrong. The future isn't going to be one giant AI that handles all of identity governance. It's going to be a fleet of narrow agents, each one auditable, each one deployed when the team is ready, each one retired or replaced as the threat shape changes.
The phrase I've started using internally is "the control plane is the agent fleet, not the model." That's the architectural bet behind Autopilot. We've built it that way because the security teams running it are operating that way.
We make autonomy boring. Boring in the way that fire suppression in a data center is boring. Specifically engineered, well-instrumented, mostly invisible, deeply trusted. That's the bar we set for Autopilot, and it's the bar we're meeting.
A few predictions, from where I sit 10 weeks in.
The identity governance category is going to fragment along the autonomy axis. Vendors who ship generic "AI-powered" features bolted onto rules engines will lose share to vendors who ship narrow, accountable agents that customers can audit, deploy, and extend. The winners will be the ones who make autonomy explicable, not the ones who make it impressive. We've made our bet, and the market is validating it in real time.
The "control plane" framing is the right one, but it goes beyond agents. Microsoft, Okta, and others are now naming their agent control surfaces. That's a market-defining moment. The deeper truth, though, is that the agent control plane only works if the identity control plane underneath it is unified. You can't govern an agent's actions if you don't have a unified record of every human, machine, service account, and agent identity in your environment. Identity becomes the substrate. The agent layer is the workload. Linx is the only platform built for both.
CISOs are going to keep telling us they want autonomy and verification together. I expect this signal to get louder, not quieter. The boards of the companies our customers serve are starting to ask "are we governable?" instead of "are we secure?" That's a more sophisticated question, and it's going to drive procurement priorities for the next two years. The platforms that answer it well will define the next decade of security.
The bar for what counts as "autonomous identity security" is going to rise quickly. Six months from now, the demo bar will be entirely different from where it is today. The bar is being set by the platforms shipping today, with skin in the game. We are one of them.
We shipped Autopilot 10 weeks ago. The conversations are different from the ones I had a year ago. Different from six months ago. Different from 10 weeks ago.
The market is moving, and it's moving toward something specific: autonomous identity governance that earns trust by showing its work. That's exactly what we built.
If you're a CISO or Head of IAM thinking about how autonomy fits into your identity program, what to deploy first, how to phase trust, where the audit trail needs to live, we'd be glad to compare notes. The companies that figure this out first won't be the ones who buy the most tools. They'll be the ones who deploy autonomy with discipline. We're doing it now. Come see what 10 weeks of shipping autonomous identity governance actually looks like.
10 weeks in, that's what I'm certain of.
Autonomous identity security is the use of AI agents to continuously monitor identity environments, evaluate risk in context, and take action in real time without waiting for human review. It replaces the periodic, alert-driven model of legacy identity governance with a continuous, agent-driven model that operates at machine speed and produces a complete audit trail of every action taken.
Autopilot is Linx Security's autonomous AI agent for identity governance. It runs as a fleet of narrow, single-purpose agents, including Admin Drift Monitor, UAR Reviewer Classifier, and Access Profile Tuner, that each perform a specific identity governance task continuously, with full action logging and customer-readable rationale on every decision. Autopilot is shipping today, with deployments and active engagements across retail, financial services, healthcare, hospitality, and Big Tech.
Legacy identity governance platforms are built around quarterly access review cycles, rule-based alerting, and human-in-the-loop decision making. Autonomous identity security is built around continuous monitoring, AI-driven contextual risk evaluation, and direct action by accountable agents. Linx Security delivers value in weeks rather than the months or years typically required by legacy IGA platforms.
The two most common first deployments are Admin Drift Monitor, which detects unauthorized administrative privilege elevation and only fires when it finds no business justification, and UAR Reviewer Classifier, which pre-classifies entitlements during access review campaigns to reduce human review time. Access Profile Tuner is the next agent shipping, continuously refining access profiles based on actual usage patterns. Teams typically extend to additional agents over the following 30 to 90 days as trust in the platform builds.
Autonomous identity security only works in regulated environments if every action the system takes produces a complete, defensible audit trail. Linx Security's Autopilot logs every action with full reasoning, the data inputs the agent used, and the policy or context that triggered the decision. This satisfies SOC 2, ISO 27001, NIST, and most regulatory frameworks while maintaining continuous autonomous operation.
Autonomous identity security is most relevant for CISOs, Heads of Identity and Access Management, and security architects at enterprises with more than 1,000 employees or significant non-human identity sprawl across service accounts, machine identities, AI agents, and contractor access. Companies operating in regulated industries (financial services, healthcare, retail, hospitality) and those running multiple legacy identity tools simultaneously typically see the fastest value from migrating to a single autonomous platform.

As identity-based breaches continue to rise and access misuse becomes a primary attack path, organizations rely on User Access Reviews (UARs) to answer two seemingly simple questions: Who can access what, and should they still be able to?
In theory, this is where stale access should be caught. In reality, it often slips by unnoticed.
Consider a common scenario: A sales operations manager moves into a revenue analytics role. Months later, during a quarterly access review, their new manager is asked to approve continued access to Salesforce admin permissions, Snowflake read access, and a legacy CRM role labeled “SalesOps_Admin_v2.” Faced with dozens of similar decisions, tight deadlines, and little context, the manager approves everything. The review is completed on time. The access persists.
As a result, risk compounds quietly. If an attacker later compromises the account, those lingering admin permissions provide a direct path into sensitive systems, and the activity may appear legitimate because the access was formally approved. By the time unusual behavior is detected, the damage may already be done, hidden behind what looks like valid access.
This article takes a closer look at what User Access Reviews are, why they often fail in enterprise environments, and what actually improves them, including how teams can evolve beyond periodic certification to continuous identity governance.
User Access Reviews, sometimes referred to as Access Certifications, are formal review processes used to confirm that individuals retain the right level of access to systems, applications, and data.
In modern environments, access needs change constantly. People join teams, move roles, take on short-term projects, and leave. Systems are added, deprecated, or reconfigured. Without a mechanism to revisit access decisions, privileges tend to accumulate.
UARs counter that drift before it turns into persistent risk, making them a key control for security and compliance programs. Security teams rely on them to reduce unnecessary access, regulators expect them, and auditors ask for evidence.
But UARs are much more than box-checking exercises: They’re crucial for combatting the consequences of outdated/over-permissive access, which include an increased blast radius, lateral movement opportunities, and data exposure. Left unchecked, excessive access can also undermine segregation of duties, increase the likelihood of insider misuse, and complicate incident response when permissions are overly broad or poorly documented.
On a technical level, a User Access Review usually evaluates three core elements:
A typical review asks an approver to confirm whether each combination of user, system, and entitlement is still required. Teams often formalize this process using a standardized User Access Review checklist to ensure reviews are consistent across systems.
Most organizations run User Access Reviews as periodic campaigns on a quarterly, semiannual, or annual basis. Security or identity teams first collect access data from identity providers, SaaS applications, and cloud platforms. The data is grouped by user or application and routed to managers, application owners, or both, depending on the organization’s review model.
In manager-led reviews, line managers are asked to certify all access for their direct reports. In application-owner models, system owners validate entitlements for all users of their application. Two-tier approaches combine both, often starting with the manager and escalating higher-risk access to application owners.
In many enterprises, these reviews are still driven by spreadsheets exported from systems that are then emailed to reviewers, tracked manually, and reconciled at the end of the cycle. Evidence is archived for audit purposes.
This model made sense when environments were smaller and change was slower. Today, it struggles to keep up.
In most enterprises, access reviews fail not because teams ignore them but because the process buckles when it meets real-world complexity.
Specifically, ineffective UARs are defined by a lack of context, unclear ownership, a “rubber-stamping” mentality, suboptimal evidence collection, and a lack of real-time coverage.
The most common UAR failure mode is a lack of context. Reviewers are asked to make decisions without understanding what the access enables.
A manager reviewing access for an engineer might see roles like “AWS_ReadOnly,” “AWS_PowerUser,” and “CustomPolicy_ProdOps.” Without visibility into what those roles allow or how they are used, the safest path becomes approval.
Ownership ambiguity compounds UAR's other failure points. In many enterprises, it’s unclear who is accountable for access: managers, application owners, or security teams. This can lead to access decisions that are delayed, inconsistently applied, or approved without meaningful inspection.
Manager-only reviews are common, but managers may not understand application-specific permissions. App-owner reviews improve technical accuracy, but app owners may not know whether access matches a user’s role.
Organizations that require approval from both the manager and the application owner improve coverage but also increase friction and review fatigue.
Faced with long lists and tight deadlines, many reviewers default to approving everything. After all, reviewers are rarely rewarded for revoking access, but they are penalized socially or operationally when revocations cause disruption. Over time, this creates a culture in which UARs are seen as a compliance chore rather than a security control.
Collecting access data across SaaS, cloud, and on-prem systems is difficult. Entitlements change. Integrations fail. Access lists go stale before reviews start. This means data is often inaccurate, incomplete, or inconsistently labeled.
Inaccuracies can be introduced downstream as well. After the review, teams must package evidence for auditors: who reviewed what, when decisions were made, and what actions were taken. In spreadsheet-driven workflows, this is a manual and error-prone process.
Even when reviews are completed carefully and on time, their impact fades quickly in dynamic environments. As we’ve seen, access changes every day as people switch roles, join new projects, or gain temporary permissions that are never revisited.
By the time a quarterly or annual review is finished, parts of it are already outdated. New access has been granted, old access has lingered, and the risk profile has shifted. The end result? Point-in-time reviews reassure auditors but only provide limited, short-lived protection for the organization.
For many teams, improving reviews means rethinking the tools they rely on. Modern User Access Review software shouldn’t just collect approvals; it should help reviewers understand risk, usage, and context in a single place. This is how organizations can start to automate User Access Reviews without sacrificing decision quality.
To understand the difference robust tooling makes, let’s walk through the principles that actually improve reviews:
Taken as a whole, these patterns explain why minor process tweaks tend to have limited impact. Real improvement comes from an approach that scales as the organization evolves.
Linx Security treats UARs as an integral part of continuous identity management, shifting teams from reactive certifications to proactive risk reduction.
Here’s how:
Most review processes treat all access the same, regardless of risk or usage. Linx starts from the opposite premise: Not all permissions matter equally.
Linx replaces access lists with clear recommendations that help reviewers focus on decisions that actually reduce risk (such as identifying unused admin roles or access that violates least-privilege expectations).
Access profiles in Linx group related permissions together so reviewers can evaluate access at the profile level rather than reviewing many individual entitlements:
Continuous governance shifts the role of access reviews. Rather than serving as the primary control, reviews act as a validation step on top of ongoing monitoring and remediation.
“Ongoing” is the key word here. Linx continuously monitors access as it changes. Rather than letting risk accumulate until the next scheduled certification cycle, Linx flags risky access combinations, unused privileges, and newly elevated roles in real time.
The Linx MCP Server exposes governance actions through policy-driven automation interfaces, allowing identity teams and automated tools to remove excessive or outdated permissions when they no longer align with role expectations or governance policies.
The main takeaway? Linx empowers teams to remediate issues immediately or queue them for review, instead of only uncovering them during a scheduled review months later.
In practice, this means UARs become shorter, more targeted, and easier to defend. Auditors still get clear certification records, but those records are backed by continuous monitoring and remediation, not last-minute cleanup.
As environments grow more complex and identity becomes the primary security perimeter, point-in-time certifications alone are no longer enough. Organizations that rely solely on periodic reviews will continue to struggle with rubber stamping, incomplete context, and access that drifts out of alignment with real-world roles. The best IGA solutions, like Linx, automate access reviews and provide real-time visibility and governance.
The path forward isn’t eliminating UARs. It’s strengthening them with context, automation, and continuous oversight so reviews become informed validation checkpoints rather than large-scale cleanup exercises.
If you want to see how continuous identity governance changes the equation, request a demo to experience Linx’s approach to User Access Reviews.
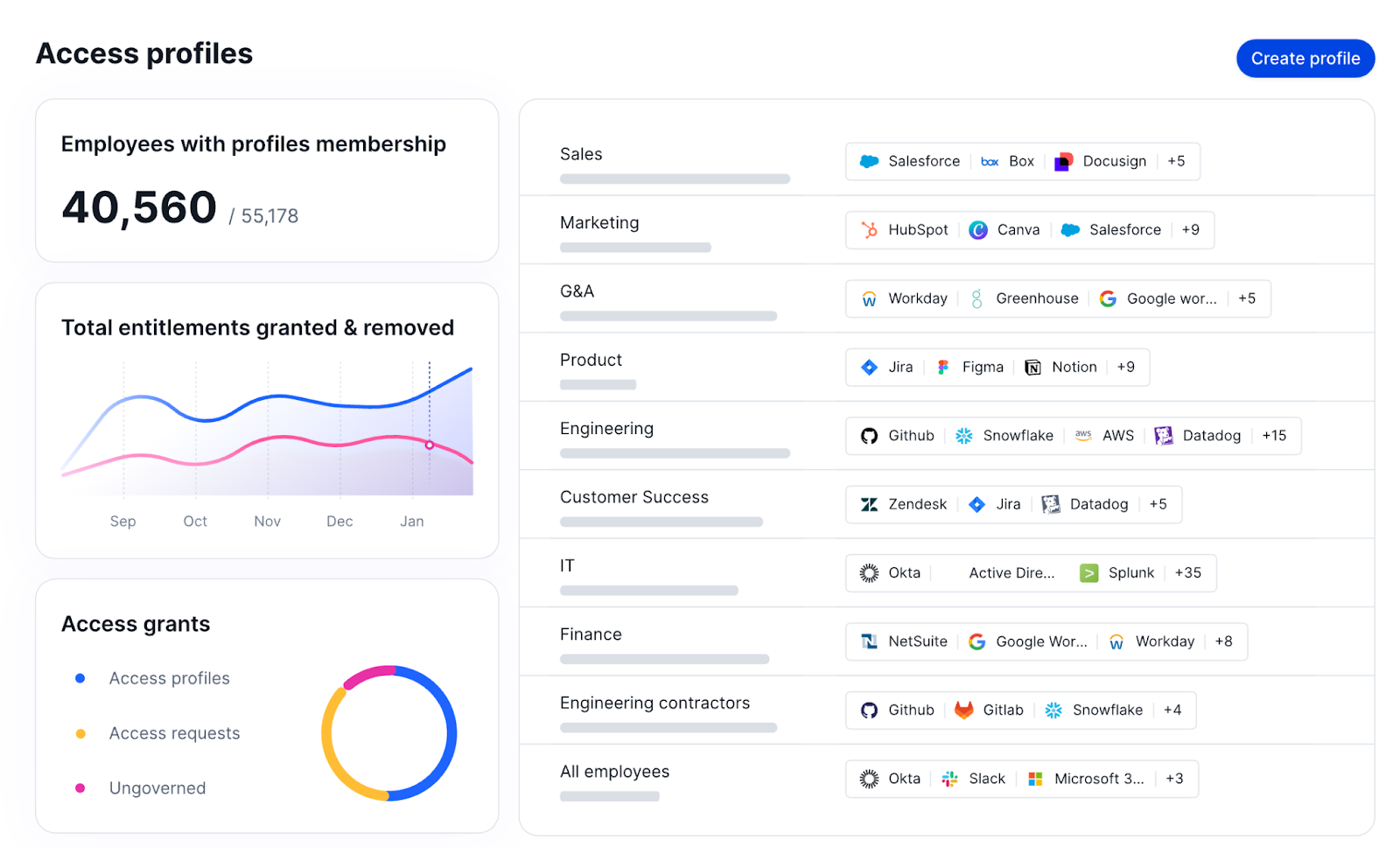
Identity governance and administration (IGA) solutions manage the lifecycle of user identities and their permissions across an entire organization, providing full coverage for on-premises, cloud, and hybrid environments. With IGA, you can control who has access to which systems, enforce policies, and provide audit trails.
IGA is critical for security. Within an organization, the number of identities can easily reach into the thousands. Employees, contractors, partners, service accounts, and principals may have access to dozens or hundreds of applications.
Without proper governance, overprivileged access can lead to breaches at scale. Attackers just need access to a single overprivileged account, and then they can move laterally until they hit the systems they’re interested in. (Read our article about the anatomy of an identity breach to learn more.)
At the core of IGA is identity lifecycle management (ILM), which is the end-to-end process of managing identities from creation and modification (for role changes) to deletion. User lifecycle management is a subset of ILM that focuses on human identities, but modern platforms extend lifecycle management to non-human identities as well.
One important note: Most IGA tools are not security tools; they’re IT administration tools built to address provisioning and lifecycle management problems. A security-first IGA solution like Linx Security evaluates every entitlement, making it easy to understand the potential damage it could cause.
Asking targeted questions is the best way to determine whether the IGA tool you’re considering will strengthen your security posture. The right questions center on the common failure points for IGA solutions, not the checkbox features every vendor supports.
Below, you’ll find a structured framework for the top 10 questions that truly matter. Each section includes context for why the question is important, real benchmarks for good and bad answers, and a discussion of how tools that fall short can lead to vulnerabilities.
Traditional IGA solutions were built for compliance, not security. Linx is different.
With Linx, you get an AI-native, security-first IGA solution. All of Linx’s features are purpose-built to give identity teams the visibility and context they need to reduce the blast radius of every identity in your organization.
Linx uses a graph-powered architecture to map every identity to every permission, resource, and relationship across your environments. It offers out-of-the-box automated remediation and a faster time to value with pre-built integrations and no-code connectors.
And with Linx Autopilot, teams can now deploy AI agents that work continuously on their behalf. Autopilot monitors identity environments 24/7, detects meaningful changes, evaluates risk in context, and takes action in real time.
Identity governance and administration solutions ensure that the right people have access to the right resources. Because a single over-privileged identity can become an entry point for a full-scale breach, the IGA solution you choose should be a security control that shows you exactly how large your blast radius is when an attack happens.
If you are ready to start selecting an IGA platform but don't know where to start, check out our blog post on the top IGA tools.
The 10 questions in this article help you separate IGA solutions that look good on paper from vendors that actually secure identities in practice. They empower you to make a choice that slashes risks and provides immediate value.
That’s where Linx stands apart.
If you’re ready to see what AI-native, graph-powered IGA looks like in practice, request a demo of Linx.
We're at one of those rare moments where an entire software category gets rewritten from scratch. Not improved. Replaced. AI isn't making identity governance faster - it's making the old architecture obsolete.
When Niv and I started Linx two years ago, we made a bet: that the identity governance category was overdue for a fundamental rethink, and that AI-native architecture - not AI bolted onto legacy infrastructure - would be what made that possible. That the future of IGA wasn't periodic reviews and manual workflows. It was continuous, autonomous, and built for a world where humans, machines, and AI agents all coexist inside the same enterprise.
Today, I'm proud to announce that Linx Security has raised a $50M Series B, led by Insight Partners, with continued support from Cyberstarts and Index Ventures - bringing our total funding to $83 million. And alongside this round, we've launched Linx Autopilot: the industry's first AI agent purpose-built for Identity Governance and Administration.
This isn't just a funding milestone. It's a signal that the IGA category is at an inflection point - and that Linx is leading it.
The identity landscape has been transformed by three forces converging at once.
First, AI agents are proliferating inside every enterprise - not as experiments, but as active participants in business workflows. They hold credentials. They access sensitive systems. They act with autonomy. And almost none of today's governance frameworks were built to manage them.
Second, the attack surface has exploded. One breach, one over-privileged service account, one dormant credential - and the damage can be catastrophic. Boards know it. CISOs feel it daily. The compliance frameworks are finally catching up.
Third - and this is what excites me most - the technology is finally ready. AI-native architecture makes it possible to do in seconds what traditional tools take weeks to accomplish: detect, evaluate risk in context, and act. Not reactively. Continuously.
IGA was always treated as a necessary evil. A compliance checkbox. Something you suffered through. We built Linx on the premise that it doesn't have to be that way.
The enterprise of 2026 doesn't look like the enterprise IGA was designed for. AI agents are being provisioned inside every workflow. Non-human identities now outnumber human ones. The attack surface isn't growing linearly - it's multiplying. And the governance frameworks built for a world of on-prem directories and annual access reviews were simply never designed for this reality.
Linx is built AI-native from the ground up - not AI layered onto legacy architecture. That distinction matters more than it might sound. It's what allows us to move from periodic, reactive governance to something fundamentally different: continuous, autonomous identity security that operates at the speed of the business and the speed of the threat.
Think of it as having a security operator working 24/7 on your behalf - one that monitors every identity in your environment, detects risk in context as it emerges, and acts before the damage is done. When a privileged account behaves unexpectedly, it responds. When an AI agent is provisioned with excessive permissions, it sees it. When an employee moves roles and leaves ghost access behind, it remediates - before an attacker finds it first.
Security teams don't lose control. They gain leverage. The tedious, repetitive work gets handled autonomously. The decisions that require human judgment get escalated. That's what modern identity governance looks like - and that's what we're delivering.
None of this happens without the people.
To Niv - twenty years of shared history, and I still learn something from you every week. Building this company alongside you has been one of the great privileges of my career. You push this product to places I wouldn't have imagined.
To Sarit - your technical vision and relentless standards are woven into every line of this platform. What you've built with the engineering team is something we'll be proud of for a long time.
To our entire Linx team - 100 people who bet on a vision and made it real. Every customer win, every product breakthrough, every late night - that's us, together. I'm incredibly proud of what we've built as a team.
To Teddie, Elan and the Insight Partners team - your belief in where this market is going gave us a true partner for the next chapter. And to Gili at Cyberstarts, and Shardul at Index Ventures - you've been with us from the beginning, and your conviction in this vision has never wavered. We don't get here without all of you.
And to our customers - the security leaders and identity practitioners who chose to build with us early, challenged us to be better, and trusted us with what matters most. You are the reason we do this. Your trust is the highest validation we know.
The market isn't just ready, it's asking for it. Every security leader we talk to, every enterprise scrambling to govern AI agents they provisioned last quarter with no visibility into what they can access, confirms what we believed two years ago: this category was overdue, and the moment is now.
What comes next is simple to say and hard to execute: we scale. We're growing the team, accelerating the Autopilot roadmap, and going deeper with the enterprises already trusting us to govern millions of identities in production.
The IGA category is being rewritten. The window to define what the next generation looks like is open.
We intend to define it.
- Israel Duanis, CEO & Co-Founder, Linx Security





